안녕하세요! 지난 포스팅에서 머신러닝의 3가지 학습 방법을 알아봤는데요, 오늘은 그중 지도학습(Supervised Learning)을 더 깊이 파헤쳐보겠습니다. 지도학습은 크게 분류(Classification)와 회귀(Regression) 두 가지로 나뉘는데, 이 둘의 차이를 정확히 이해하는 것이 머신러닝 학습의 핵심입니다!
분류 vs 회귀: 한눈에 비교하기
가장 중요한 차이점은 바로 예측하려는 값의 성질입니다. 범주를 예측하면 분류, 연속적인 숫자를 예측하면 회귀입니다!
1. 분류 (Classification): 어느 그룹에 속할까?
분류는 데이터를 미리 정의된 범주(카테고리) 중 하나로 분류하는 문제입니다. 마치 시험지를 채점해서 합격/불합격을 판단하거나, 과일을 보고 사과인지 바나나인지 구분하는 것과 같습니다.
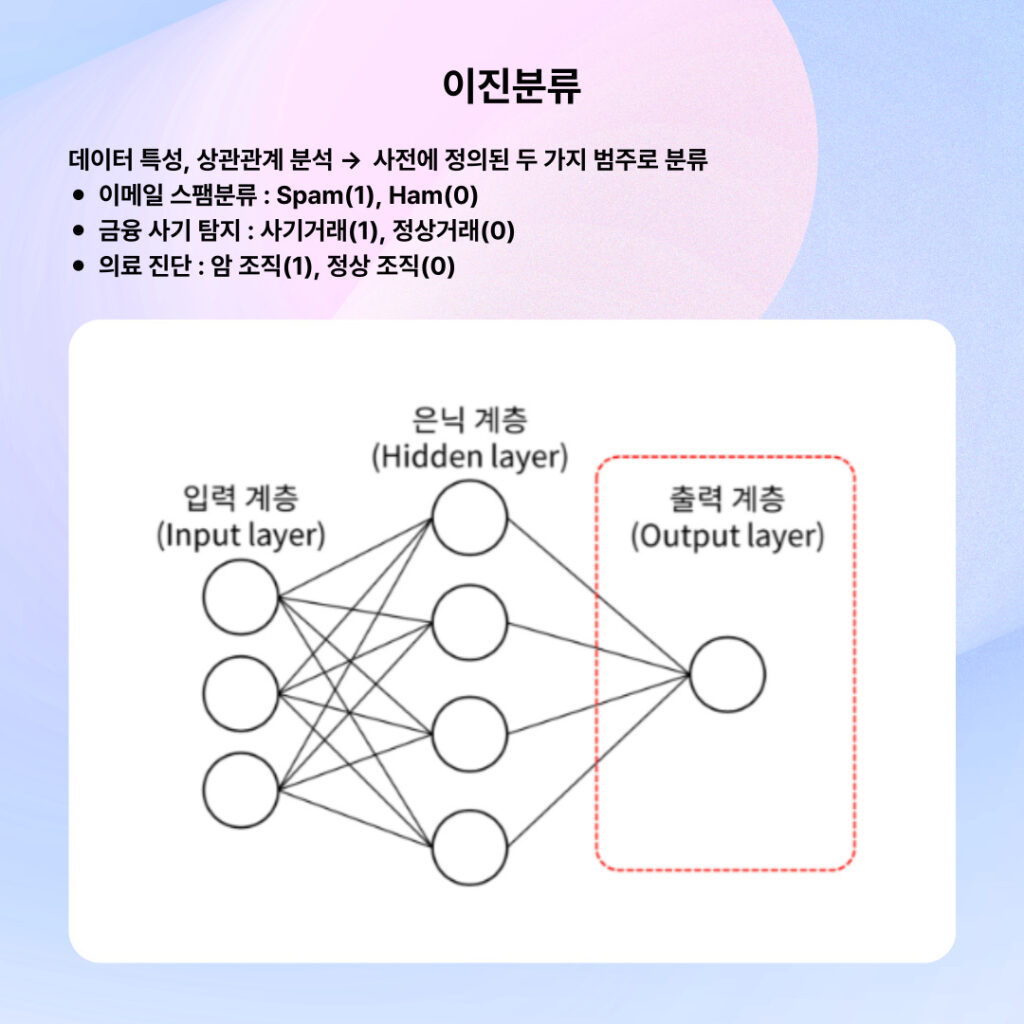
📌 이진 분류 (Binary Classification)
개념 두 가지 범주 중 하나를 선택하는 문제입니다. Yes or No, 0 or 1과 같이 두 가지 경우의 수만 존재합니다.
실생활 예시
- 이메일: 스팸 / 정상 메일
- 의료 진단: 질병 있음 / 질병 없음
- 대출 심사: 승인 / 거절
- 고객 이탈: 이탈 예상 / 유지 예상
작동 원리
모델은 각 클래스에 속할 확률을 계산하고, 더 높은 확률을 가진 클래스를 최종 결과로 출력합니다. 대부분 50%를 기준(threshold)으로 판단하지만, 상황에 따라 이 기준을 조정할 수 있습니다.
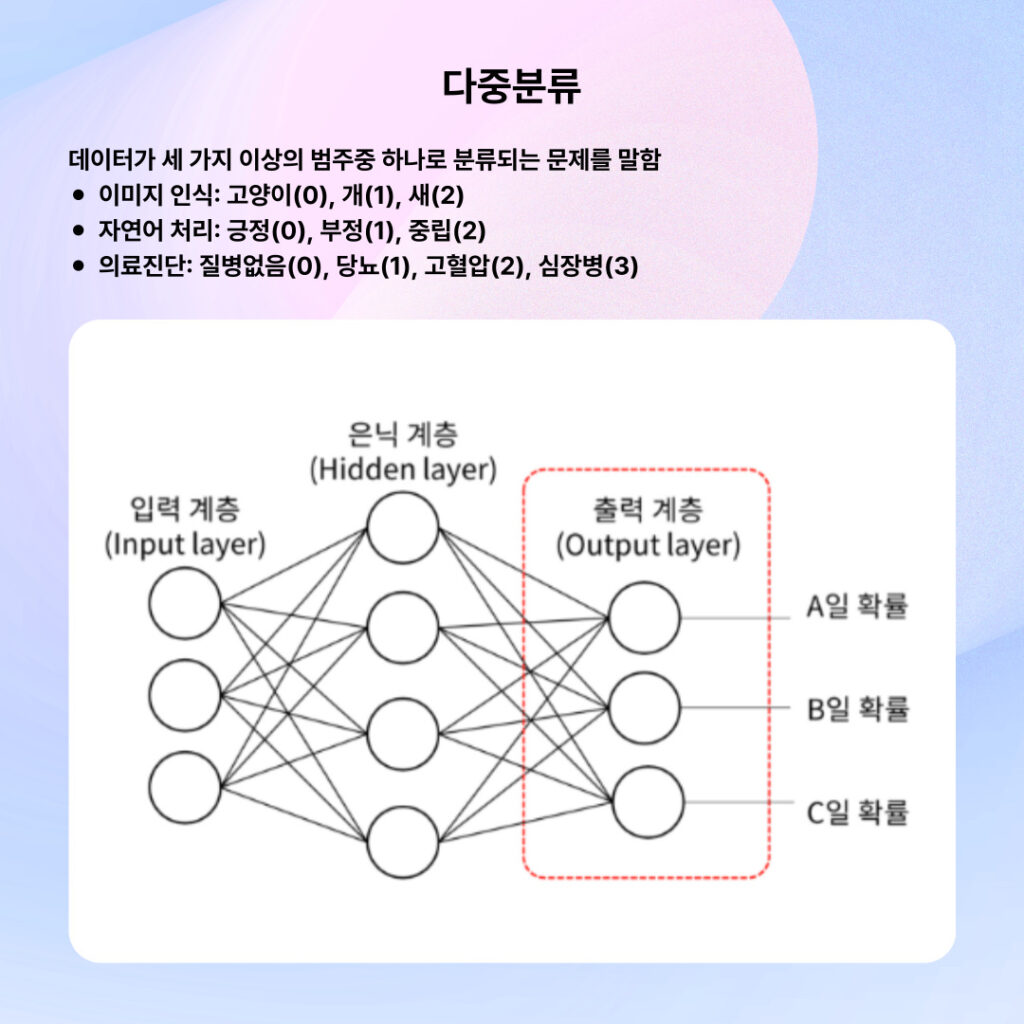
📌 다중 분류 (Multiclass Classification)
개념 3개 이상의 범주 중 하나를 선택하는 문제입니다. 이진 분류를 확장한 형태라고 생각하시면 됩니다.
실생활 예시
- 학점: A / B / C / D / F
- 붓꽃 종류: Setosa / Versicolor / Virginica
- 뉴스 카테고리: 정치 / 경제 / 사회 / 문화 / 스포츠
- 감정 분석: 긍정 / 중립 / 부정
작동 원리
다중 분류에서는 모든 클래스에 대한 확률을 계산하고, 가장 높은 확률을 가진 클래스를 최종 결과로 선택합니다. 모든 확률의 합은 100%가 됩니다.
🎯 분류 문제의 핵심 특징
1. 결과가 불연속적입니다
- 합격과 불합격 사이에는 중간값이 없습니다
- “80% 합격”이라는 상태는 존재하지 않습니다
- 반드시 하나의 범주에 속합니다
2. 확률을 출력합니다
- 모델은 각 클래스에 속할 확률을 계산합니다
- 이를 통해 예측의 확신 정도를 알 수 있습니다
- 예: “이 이메일이 스팸일 확률은 95%입니다”
3. 평가 지표가 다릅니다
- 정확도(Accuracy)
- 정밀도(Precision)와 재현율(Recall)
- F1-Score
- ROC-AUC
2. 회귀 (Regression): 얼마나 될까?
회귀는 연속적인 숫자 값을 예측하는 문제입니다. “얼마나”, “몇 개”, “어느 정도”처럼 구체적인 수치를 알고 싶을 때 사용합니다.
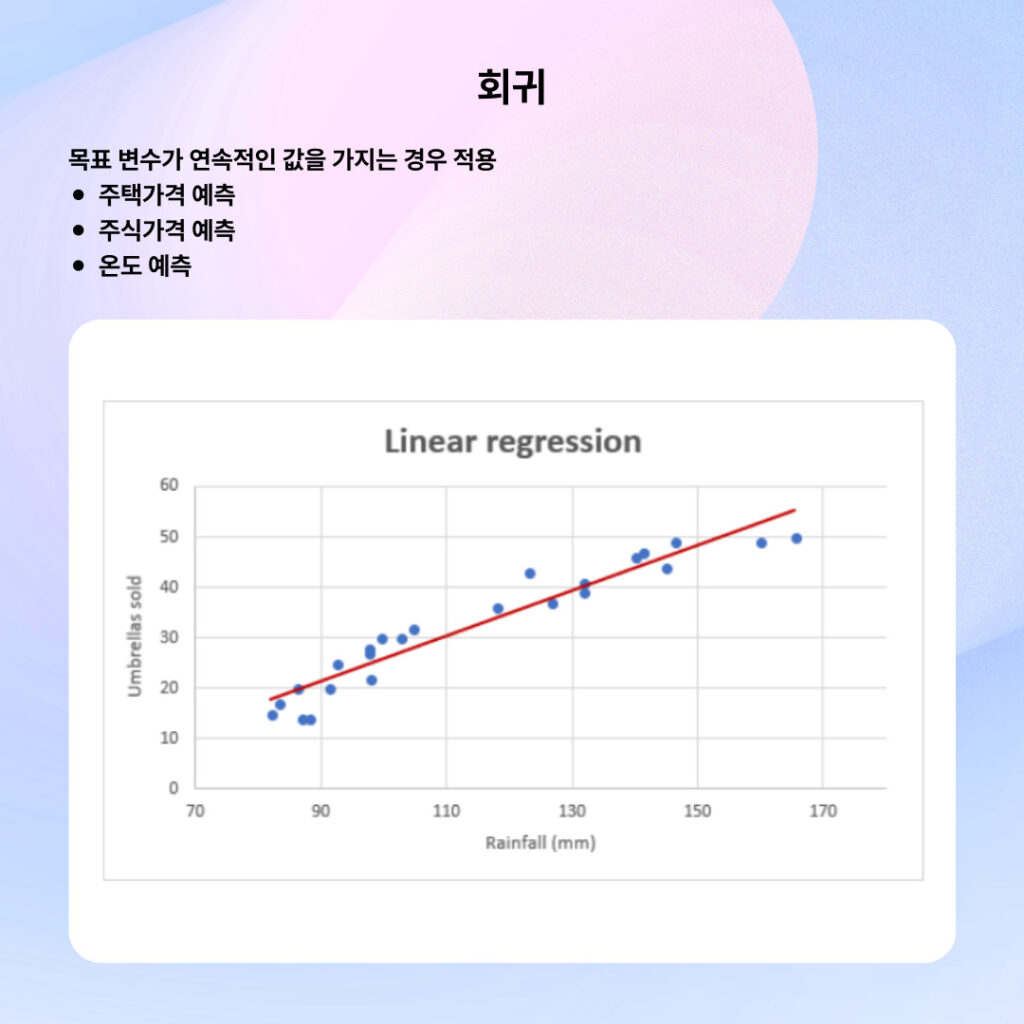
📌 회귀의 핵심 개념
특징
- 예측값이 연속적인 범위 내에 존재
- 무한히 많은 가능한 값 중 하나를 예측
- 예측 결과 간에 순서와 크기의 의미가 있음
실생활 예시
- 부동산: 아파트 매매가 예측
- 날씨: 내일 최고 기온 예측
- 비즈니스: 다음 달 매출액 예측
- 제조: 제품 생산량 예측
- 교통: 택시 요금 예측
🔄 회귀 vs 분류의 차이 체감하기
같은 데이터, 다른 문제
온라인 쇼핑몰의 고객 데이터로 두 가지 다른 문제를 풀어봅시다.
회귀 문제: “이 고객이 다음 달에 얼마를 지출할까?”
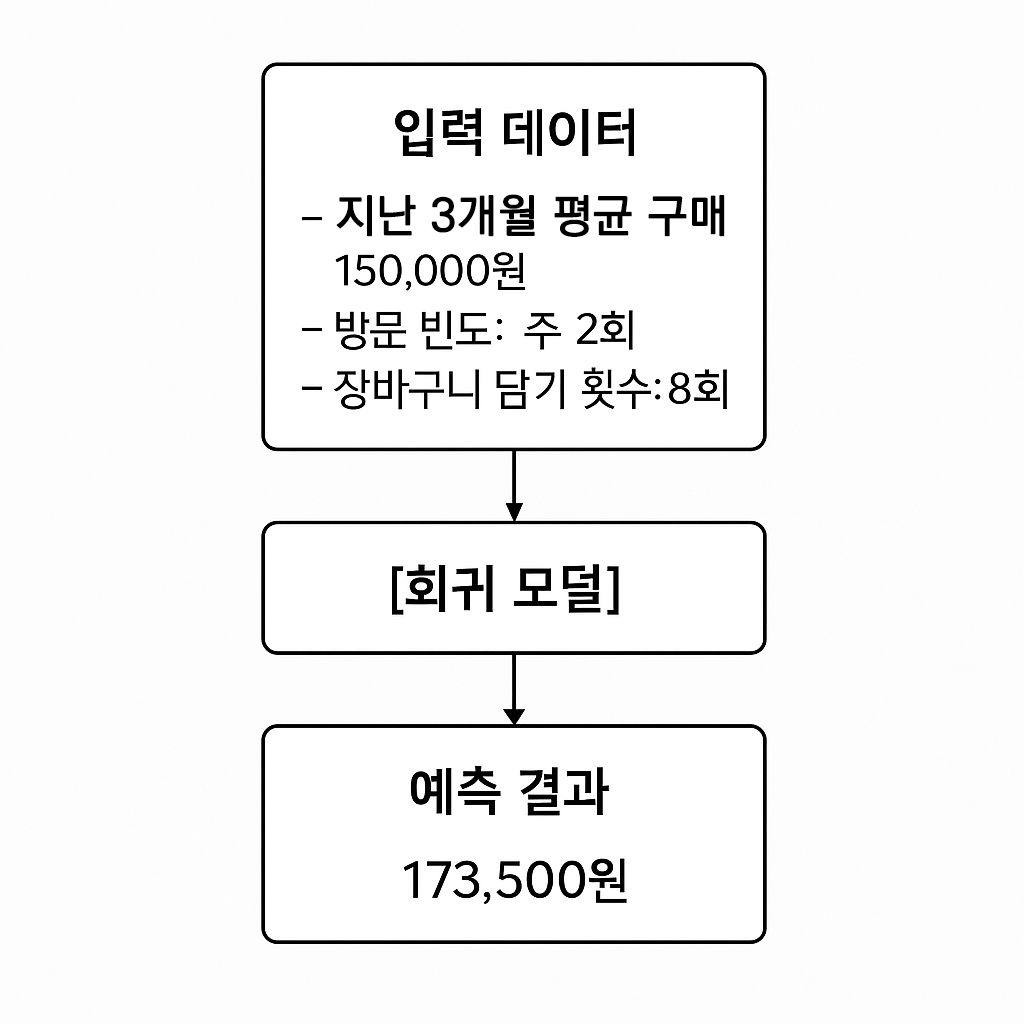
분류 문제: “이 고객이 다음 달에 구매할까?”
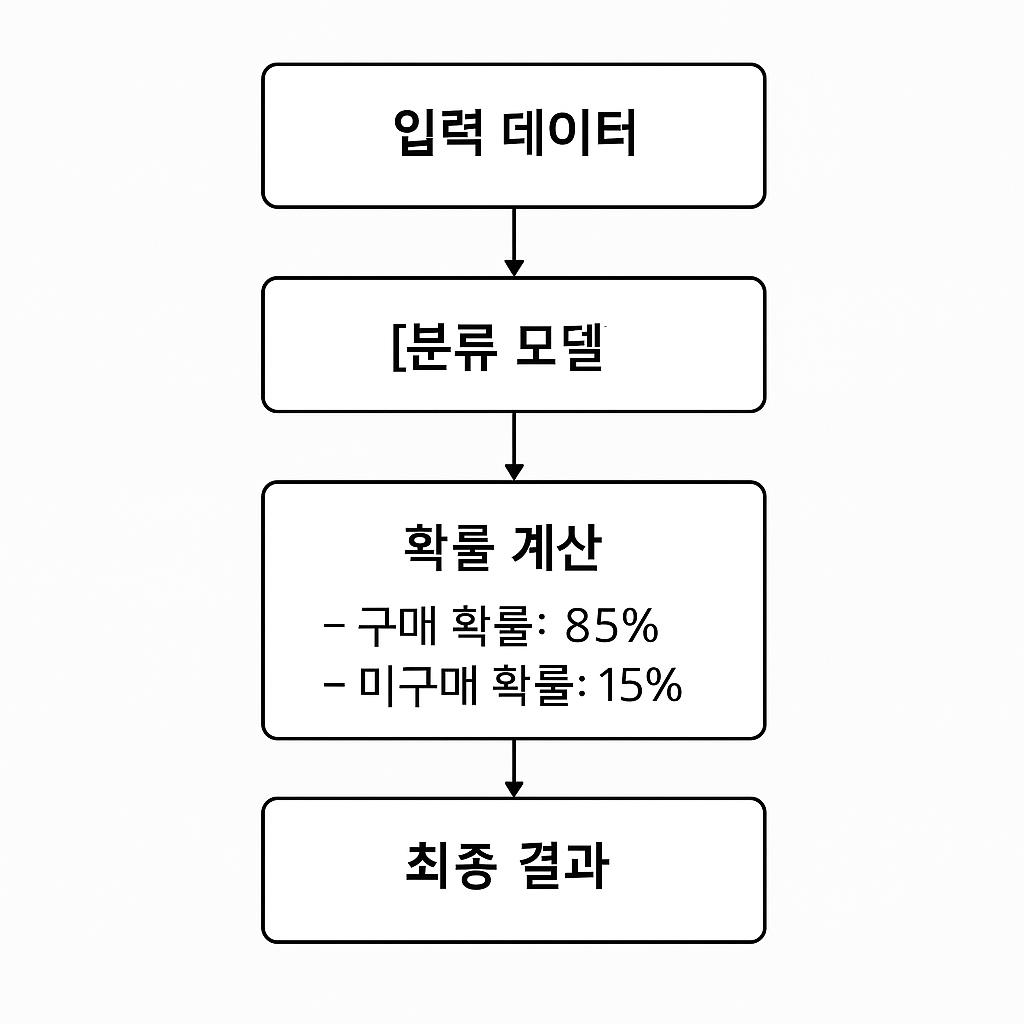
🎯 회귀 문제의 핵심 특징
1. 결과가 연속적입니다
- 집값: 3억 2,500만원, 3억 2,501만원… (무한히 세분화 가능)
- 온도: 23.5도, 23.51도, 23.511도…
- 매출: 1,234,567원 (정확한 숫자)
2. 숫자 자체를 출력합니다
- 확률이 아닌 실제 예측값을 제공
- 예: “내일 최고 기온은 23.5도입니다”
3. 평가 지표가 다릅니다
- MSE (Mean Squared Error)
- RMSE (Root Mean Squared Error)
- MAE (Mean Absolute Error)
- R² (결정계수)
💡 분류 vs 회귀 구분하는 꿀팁
실전에서 문제를 만났을 때, 분류인지 회귀인지 헷갈린다면 다음 질문들을 해보세요.
✅ 체크리스트
1. 예측 결과의 개수를 셀 수 있나요?
- YES → 분류 (예: 합격/불합격 2개, A/B/C/D/F 5개)
- NO → 회귀 (예: 집값은 무한히 많은 값 가능)
2. 예측 결과 사이에 중간값이 의미가 있나요?
- YES → 회귀 (예: 999권과 1,000권 사이에 999.5권이 의미 있음)
- NO → 분류 (예: 합격과 불합격 사이는 없음)
3. “얼마나?”라는 질문에 답하나요?
- YES → 회귀
- NO → 분류
📝 실전 연습 문제
다음 문제들이 분류인지 회귀인지 구분해보세요!
- 내일 비가 올까? → 분류 (비 옴/안 옴)
- 내일 강수량은 몇 mm일까? → 회귀 (연속적인 수치)
- 이 환자는 어떤 질병일까? → 분류 (질병 A/B/C)
- 이 학생의 최종 점수는? → 회귀 (0~100점 사이 연속값)
- 고객 등급은? → 분류 (VIP/Gold/Silver)
- 다음 달 매출은? → 회귀 (금액)
- 이 영화 리뷰는 긍정/부정? → 분류
- 이 영화의 평점은? → 회귀 (1.0~5.0점)
🔍 헷갈리기 쉬운 경우
“도서 판매량 1,000권 vs 999권”
이 경우는 숫자이지만 연속성이 핵심입니다.
- 999권과 1,000권 사이의 999.5권이 의미가 있나요? → YES
- 판매량이 999.7권일 수 있나요? → 실제론 정수지만, 예측값은 연속적
- 따라서 회귀 문제입니다!
실무에서는 판매량을 997.3권처럼 소수점으로 예측한 후, 필요에 따라 반올림합니다.
📊 그래프로 이해하기
분류 문제의 시각화
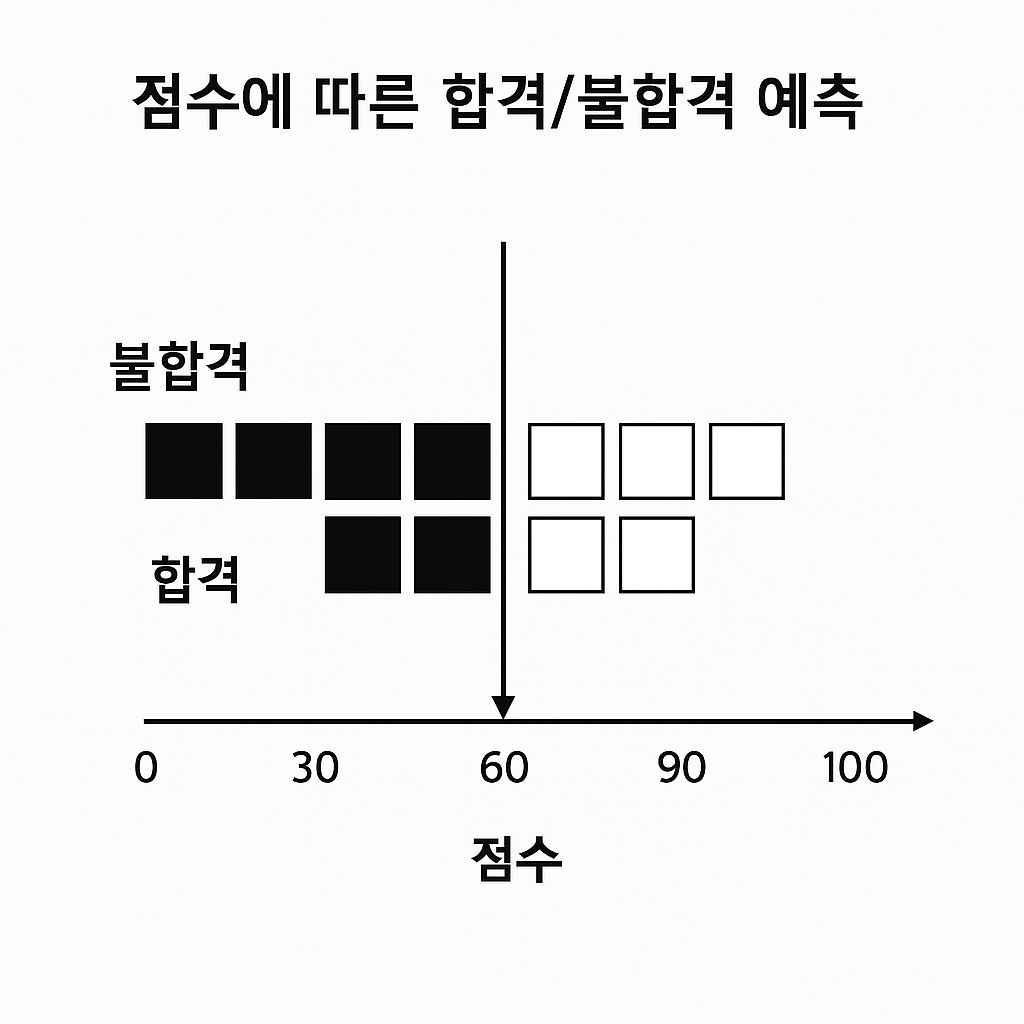
분류는 데이터를 명확한 경계로 구분합니다. 모델은 이 경계선을 학습합니다.
회귀 문제의 시각화
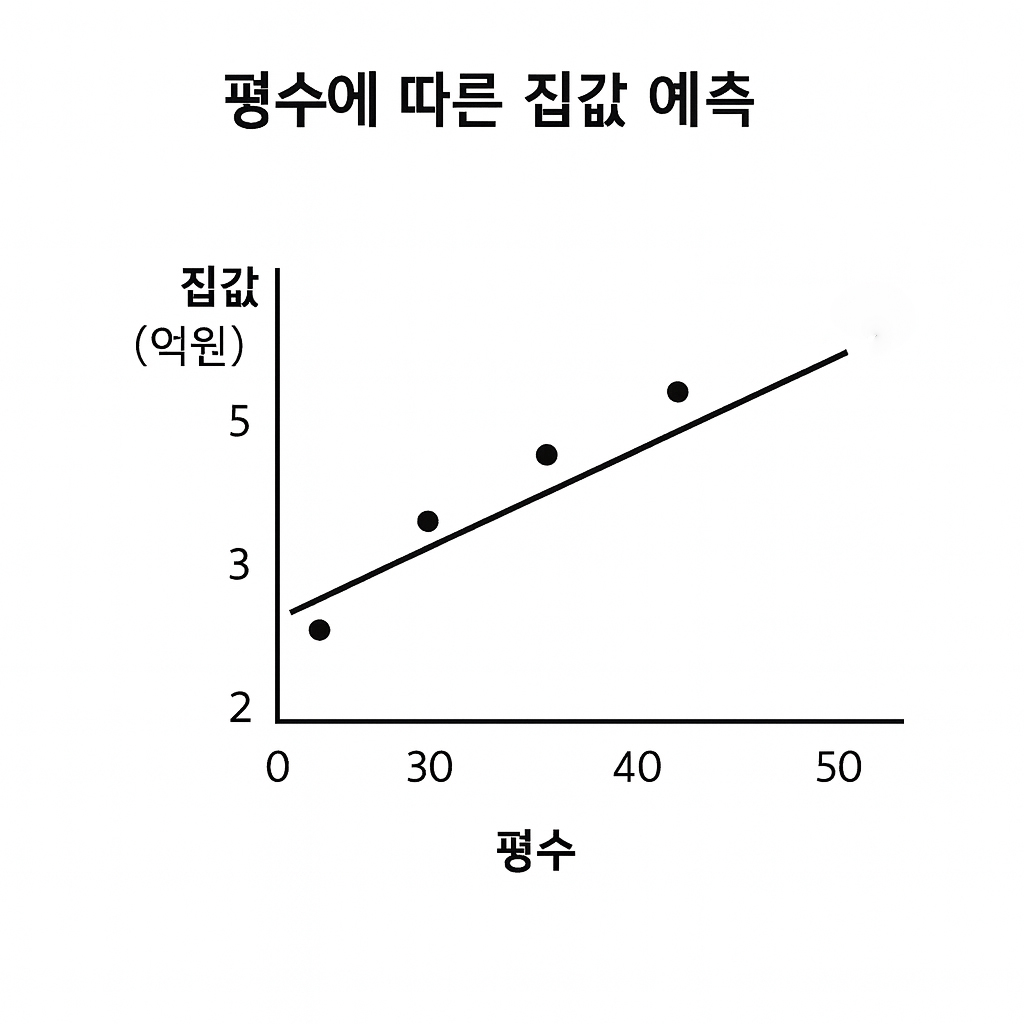
회귀는 데이터의 추세를 학습하여 연속적인 선(또는 곡선)을 만듭니다.
🎓 학습 로드맵
초급 단계: 분류부터 시작
- 이진 분류 마스터
- 로지스틱 회귀로 시작
- 의사결정나무 실습
- 혼동행렬(Confusion Matrix) 이해하기
- 다중 분류 도전
- 붓꽃 데이터셋으로 연습
- 소프트맥스 함수 이해하기
중급 단계: 회귀 정복
- 선형 회귀 기초
- 집값 예측 프로젝트
- MSE, RMSE 계산 실습
- 비선형 회귀
- 다항 회귀
- 랜덤 포레스트 회귀
실전 팁
- 분류와 회귀를 동시에 사용하는 경우도 있습니다
- 예: 고객이 이탈할지 예측(분류) + 이탈까지 남은 일수 예측(회귀)
- 문제 정의가 가장 중요합니다
- 같은 데이터도 질문에 따라 분류/회귀가 달라집니다
- 비즈니스 목표를 명확히 하고 문제를 정의하세요
마치며
분류와 회귀의 차이를 정확히 이해하는 것은 머신러닝 프로젝트의 시작점입니다. 문제를 올바르게 정의해야 적절한 알고리즘을 선택하고, 올바른 평가지표로 모델을 평가할 수 있습니다.
핵심을 다시 한번 정리하면:
- 분류: “어느 그룹?” → 확률 → 범주 선택
- 회귀: “얼마나?” → 숫자 → 연속값 예측
처음에는 헷갈릴 수 있지만, 여러 예제를 접하다 보면 자연스럽게 구분할 수 있게 됩니다. 실습을 통해 직접 경험해보는 것이 가장 확실한 학습 방법이니, 작은 프로젝트부터 시작해보세요!
다음 포스팅에서는 분류와 회귀에서 각각 사용되는 대표적인 알고리즘들을 자세히 알아보겠습니다. 궁금한 점이 있다면 댓글로 남겨주세요! 💪📈
